Protein Quantitation
Developed to meet the demands of sample limitations and throughput
Accurate relative protein quantitation is one of the cornerstones of quantitative proteomics. It is essential to the proper understanding of biological assemblies or for biomarker panels discovery experiments. The unique combination of speed, selectivity, sensitivity and robustness delivered by Bruker’s proteomics solutions allow users to obtain reliable quantitative information for more proteins while working from limited amount and/or short gradient times.
PASEF®-LFQ and 4D-Match Between Runs (MBR): get the best from two worlds
Typical challenges in non-targeted protein quantitation are the cycle time (defining the chromatographic peak resolution), the uniqueness of the ion(s) chosen to determine a peptide amount (selectivity) and the system sensitivity (quantitation of low-abundance compounds). MS-based approaches provide comprehensive quantitative results but overlapping ions reduce the selectivity of these workflows. MS/MS (DIA) based quantitation provides excellent selectivity at the cost of reduced sensitivity.
TIMS-PASEF® based label-free quantitation (PASEF®-LFQ) combines the best of both approaches. TIMS provides both an additional dimension of separation, greatly increasing selectivity, while the preconcentration effect of the TIMS cell provides greater sensitivity. The PASEF® cycle time is compatible with narrow nano-UHPLC peaks while its speed (>100 Hz MS/MS) greatly improves the reproducibility of parent ion selection compared to traditional DDA approaches.
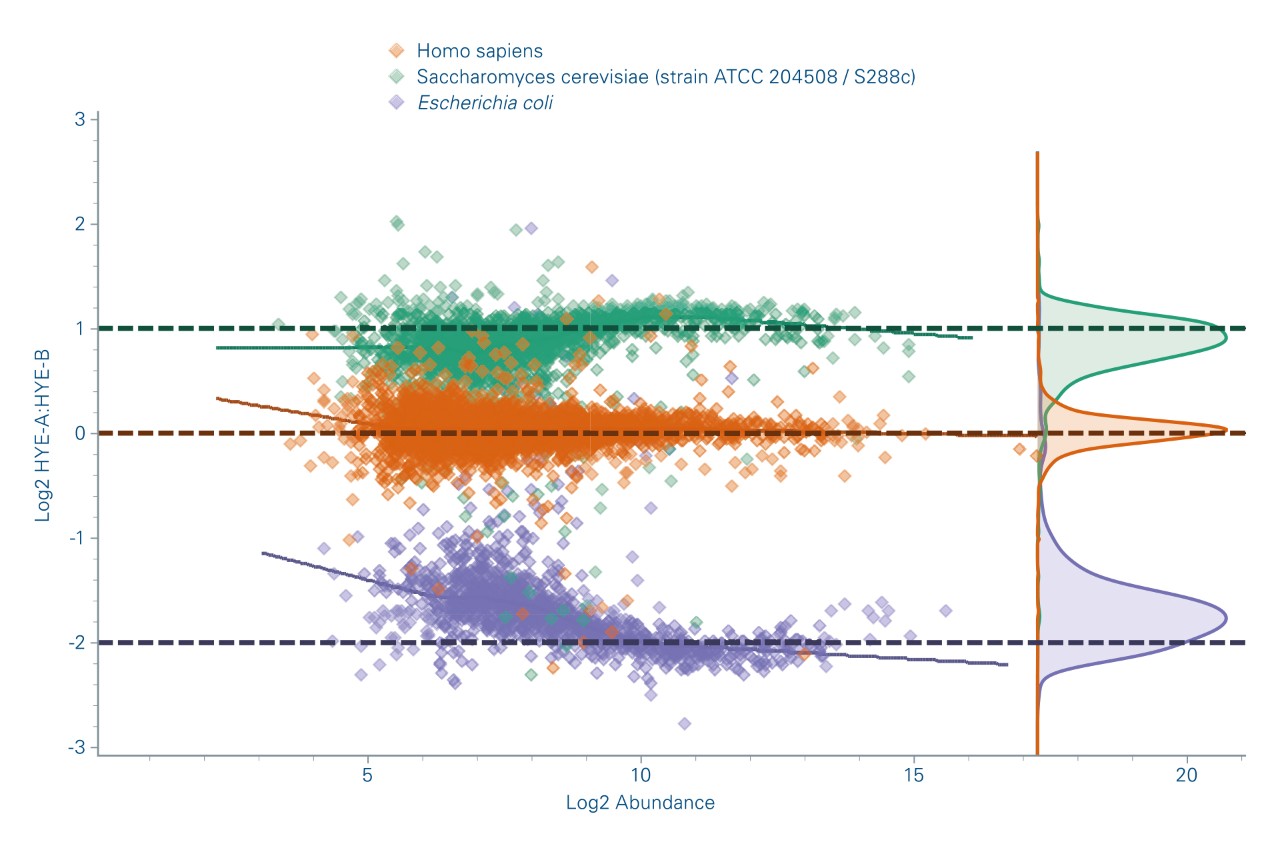
In this case, the timsTOF Pro’s unique 4D-MBR approach allows to overcome the missing value problem with an unprecedented sensitivity.
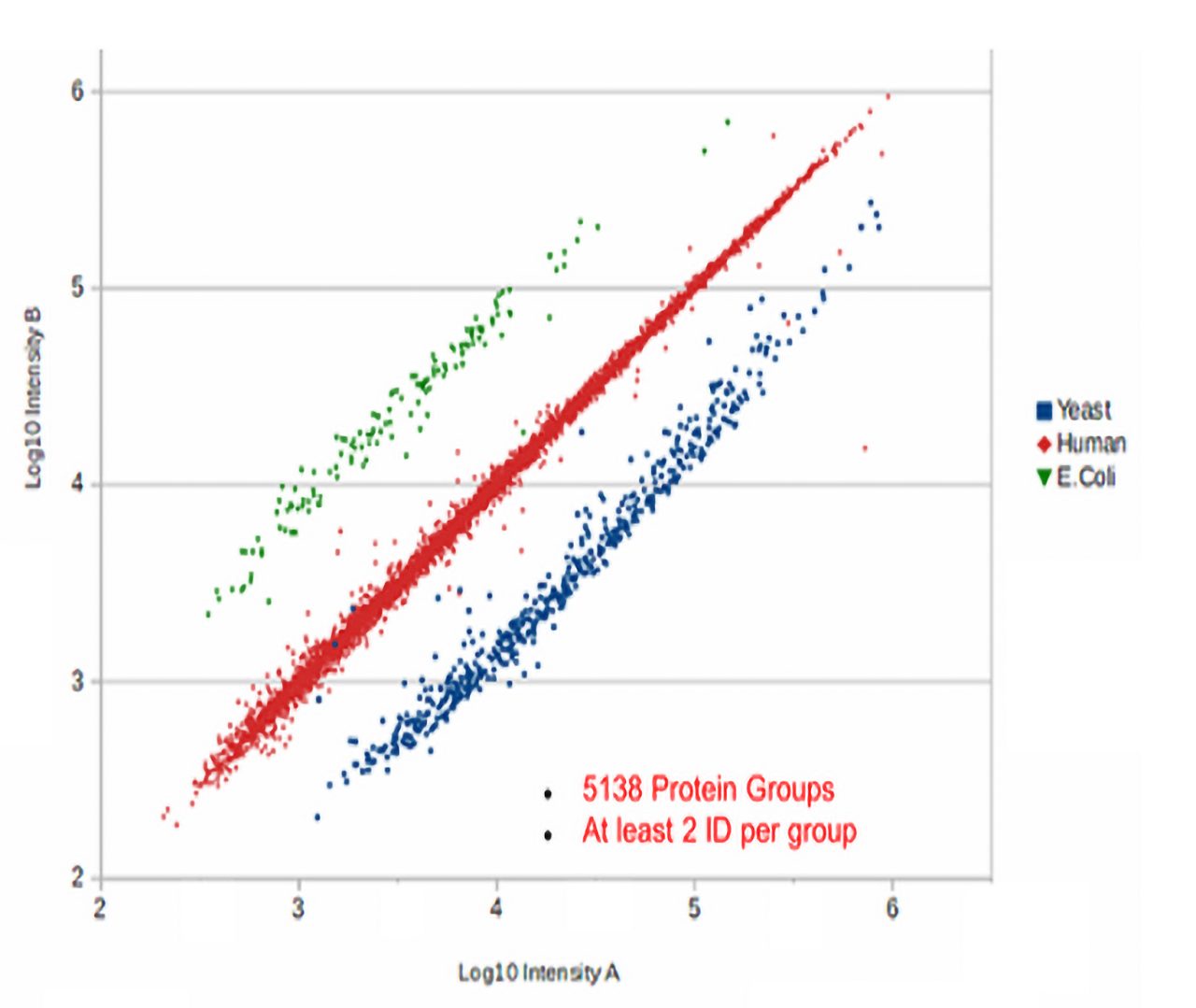
Enter the 4th dimension
In some cases, highly complex samples or short gradient analysis, the 100 Hz MS/MS repletion rate is not sufficient to reproducibly select the same ions over a large set of analyses
In this case reproducible Collisional Cross Section determination (mobility) enables 4D-Match Between Runs (MBR) which maximizes the number of proteins quantified from Label Free Quantification experiments while maintaining the highest level of confidence for high throughput sample analysis. The 4D-MBR approach is supported by the latest PEAKS and MaxQuant versions. Read our corresponding LC-MS154 application note.
Stepping into the future: introducing dia-PASEF®
For data independent acquisition (DIA), dia-PASEF® leverages the correlation between molecular mass and mobility to target the densest peptide region. The extra dimension results in increased selectivity, increased sensitivity and shorter cycle times. For more information on how dia-PASEF® pushes the limits of 4D-Proteomics™, read our LC-MS157 application note.
Advanced proteomics processing software
MaxQuant data processing
MaxQuant, the popular, powerful, open-source software fully supports PASEF®-LFQ data enabling advanced quantitation, visualization and reporting.
Advanced software support
An increasing number of advanced proteomics processing software packages now directly read the timsTOF PRO raw data: this includes Skyline, Gene Data, the complete Protein Metrics suite, Mascot Distiller
PEAKS data processing
PEAKS Studio is powered by high performance feature extraction from tims data files, obtaining high quality results in peptide-based protein identification, label-free quantitation and DeNovo sequencing. Multiple sophisticated visualization and exporting capacities allow users to review, share or refine results from multiple proteomics analyses.
Biognosys data processing
Biognosys offers a complete suite of next-generation proteomics software products. Spectronaut software aims at analyzing large-scale data-independent acquisition proteomics experiments and fully supports dia-PASEF® data using both library-based and library-free processing. PASEF® data processing is fully supported in Biognosys’ SpectroMine software.
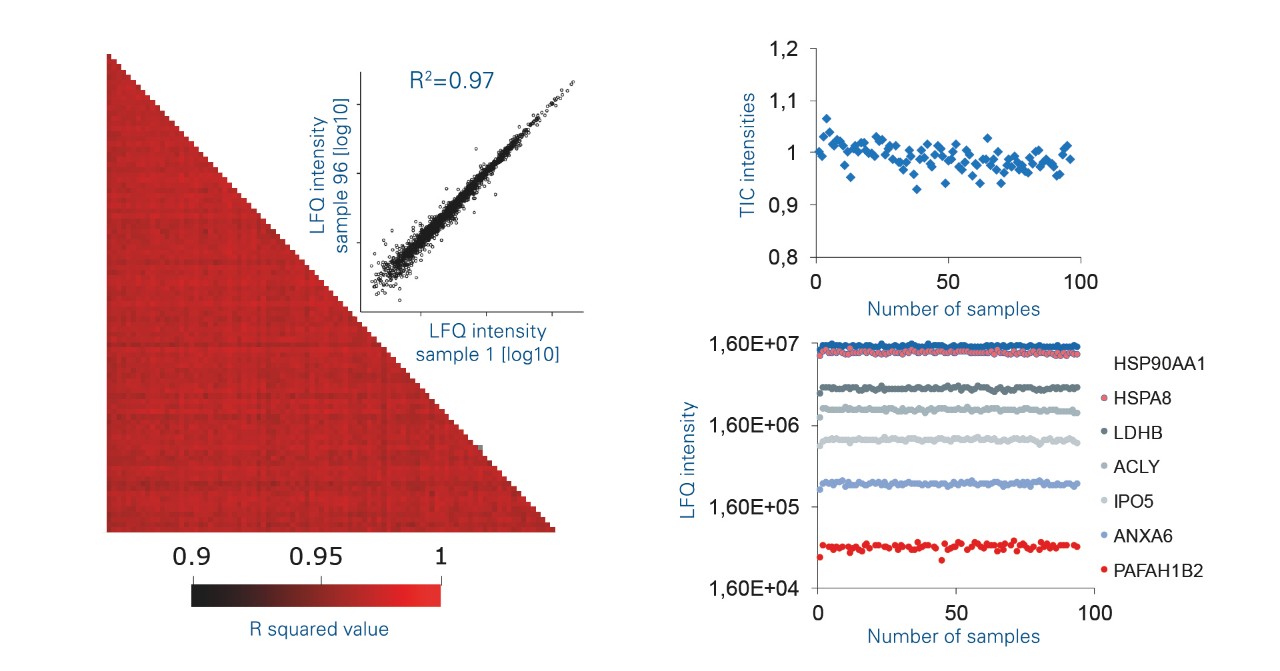
Get ready for high-throughput clinical research
The unique ability of the timsTOF Pro to deliver sustainable performance over thousands of injections combined with the enhanced LFQ performance make the system an ideal platform for high-throughput clinical research.
Data processing is key for protein quantitation and the PASEF®-LFQ approach is already supported by some of the most powerful software suites.






For Research Use Only. Not for use in clinical diagnostic procedures.