
Episode 5: Challenges of Biomedical Image Analysis in Light-Sheet Microscopy
Episode 5: Challenges of Biomedical Image Analysis in Light-Sheet Microscopy
Light-sheet fluorescence microscopy (LSFM) has changed how we study biological systems in multiple dimensions, and it has been named Nature Method of the Year 2014 1. But with its promise comes the reality: data are enormous, metadata is often messy, and analysis can be computationally demanding in ways that defy traditional image analysis pipelines.
In Episode 5 of The Light-Sheet Chronicles Podcast, we spoke with Dr. Kate McDole (MRC LMB, Cambridge) and Dr. Jan Roden (Senior Software Architect, Bruker) about biomedical image analysis. What emerged was a candid, technically rich discussion about image registration, cell tracking in lineage tracing, and data handling.
Listen to this episode or scroll down to read more about the topics discussed.
Cell Tracking to Understand Cell Lineages and Fate
Kate McDole’s lab at the MRC LMB works on scales from single cells to whole organisms. What sounds scientifically enticing can be computationally unforgiving. For example, a single early-stage mouse embryo is comprised of thousands of cells. In Kate’s lab, her team follows each one of these thousands of cells to understand its individual trajectory through space, time, division, and fate specification 2. Capturing those trajectories is already a major challenge, but analyzing them quantitatively with biomedical image analysis requires a multi-layer approach built on interdisciplinary expertise and experience.
For the McDole lab, one major focus is to optimize image acquisition, where the McDole lab is implementing more and more algorithms that are event-driven to create datasets that are meaningful to answering biological questions 3. Such as performing lineage tracing from the moment a cell is formed, to where the cell is differentiated and at its final destination.
For this, highly accurate image processing is needed. Like with segmentation, where even a modest drop in signal-to-noise produces fusions, splits, and identity swaps of cells that then cascade into erroneous lineage trees. The hope is that some of this erroneous cell identification can be corrected using deep learning approaches, especially when cells overlap or cell boundaries aren’t entirely clear for traditional methods 4.
To achieve this, the Kate McDole lab works on using predictive neural models that learn motion priors. Instead of trusting only what the pixels say at a specific moment, the models encode biological plausibility. For example, if two nuclei are tracked over time and then appear to merge in a low-quality timepoint, the system infers whether they should merge based on embryonic geometry, local lineage history, and plausibility.
TABLE OF CONTENTS:
- Tracking the Whole Organism: When Samples Drift, Swim, or Grow Out of View
- Registration: A Crucial Foundation for the Entire Pipeline
- Sparse Data, Mosaic Labels, and What Happens When Registration Can’t Be Done
- The Data Deluge: When Your Microscope Outputs Terabytes Before Lunch
- Toward a Better Ecosystem for High-Dimensional Biological Imaging
- Conclusion
- References
Timelapses and Lineage Tracing: To Quantify Means to Register
And yet, even for the most sophisticated image analysis methods, one truth remains: when registration fails, tracking fails.
As many of us have experienced, in most timelapses, the sample does not simply stay perfectly still in the center of the image (be that due to drift, growth, or other factors). Thus, to accurately trace lineages, data have to be registered first.
LEARN MORE ABOUT IMAGE ANALYSIS:
Tracking the Whole Organism: When Samples Drift, Swim, or Grow Out of View
Another approach to registration is to use it during image acquisition for sample tracking. This solves a foundational experimental problem, namely, to maintain a stable imaging frame despite biological behaviours.
Real-time sample tracking relies on continuous 3D registration between incoming timepoints and the template (e.g., baseline reference or prior timepoint). When displacement exceeds a configurable threshold, the software triggers corrective stage movements to recenter the sample. This is vital not only for drifting specimens but for biological systems where active tracking is needed, such as plant root elongation.
This is where light-sheet microscopy can become a feedback-loop imaging platform. The instrument observes, interprets, and corrects, integrating registration into a dynamic feedback-control system, rather than applying it only in post-processing.
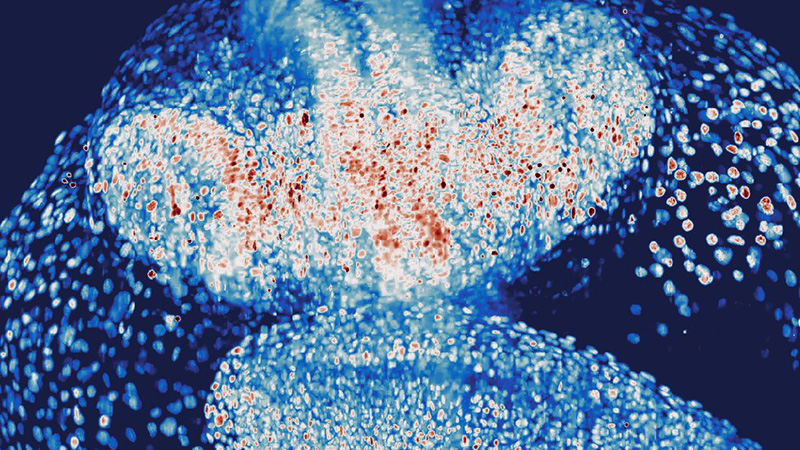
Registration: A Crucial Foundation for the Entire Pipeline
Multi-view light-sheet imaging depends on acquiring complementary optical views—orthogonal, rotated, or mirrored—each encoding different regions. To fuse data from different views into a coherent 3D representation, image registration must be as accurate as possible.
A misalignment of even a single voxel layer can compound during multi-view deconvolution, producing blurred structures, duplicated membranes, and artificial discontinuities. When the downstream goal is understanding spatial relationships, such errors propagate into becoming biologically misleading (e.g., duplicated membranes) 5.
Computationally, image registration can be highly complex, and the complexity is amplified when optical distortions enter the scene. Orthogonal objectives rarely share identical refractive indices across the sample volume, meaning global transforms can be insufficient. The true challenge is at the local level, requiring elastic, non-rigid registration algorithms that compensate for tissue deformation, local artifacts, and heterogeneity across depths 6. All that, without introducing artifacts, hallucinations, and errors themselves.
Sparse Data, Mosaic Labels, and What Happens When Registration Can’t Be Done
Light-sheet imaging often grapples with sparse labeling, such as when reporter lines illuminate only select cells or structures. For example, blood vessel data contains 3-15% of data, which makes the data unnecessarily large and sometimes even contributes to algorithms being biased towards background 7, 8. Sparse data make automated registration incredibly challenging as they often rely on sufficiently dense spatial information to compute correspondences.
One approach to overcome this is that Kate’s team uses a second channel with a ubiquitous marker for the registration, which is then also applied to the sparsely labeled first channel. When even that fails, landmark-based manual registration can be a fallback option, or worst-case the dataset is discarded. The reality is that acquiring new data is often cheaper than trying to rescue and store “bad” data.
Another interesting point raised in this podcast was that while fiduciary beads were often used in the early days of LSFM for image registration, they cannot be reliably embedded into non-gelled embryo mountings and are thus not really used. Both guests agreed: bead-based registration is elegant in principle but rarely feasible in practice.
The Data Deluge: When Your Microscope Outputs Terabytes Before Lunch
While we don’t want to complain about having data, especially lots of it, the reality is that many light-sheet datasets are too big for many scientific ecosystems that use them. Many of us will have had to send hard drives back and forth at one point or another!
A common temptation is to store only derivative results, such as segmentation masks, lineage trees, and mesh reconstructions. But that risks losing the raw data that future algorithms might interpret differently (and oftentimes we learn the most from studying raw data during data exploration).
This produces uncomfortable but necessary decisions:
- Which data are kept?
- Which recordings justify terabytes of cold storage?
- Which imperfect datasets are purged despite containing information that might prove valuable later?
And it’s not just in this podcast that this reality of data handling is discussed; it is a reality for the research community and reflected in many conferences.
Toward a Better Ecosystem for High-Dimensional Biological Imaging
The field is advancing rapidly, but the infrastructure currently lags behind the science.
The data frontier will require:
- Semantic compression methods that reduce redundancy without losing biological meaning
- Centralized storage and computing to reduce read/write times and the storage of intermediate data versions
- Architecture-level support in microscopes for on-the-fly denoising, registration, and compression
- Federated repositories that enable data access without full replication
- Pervasive metadata standards that allow cross-embryo registration and inter-study comparisons
Light-sheet microscopy is no longer merely about how to acquire beautiful data; it is an ecosystem challenge where acquisition, processing, and data handling need to be as efficient and real-time as possible. Solving these problems will require not just better software or faster hardware, but a fundamental rethinking of how biological data is generated, curated, shared, and valued.
LEARN MORE ABOUT IMAGE ANALYSIS:
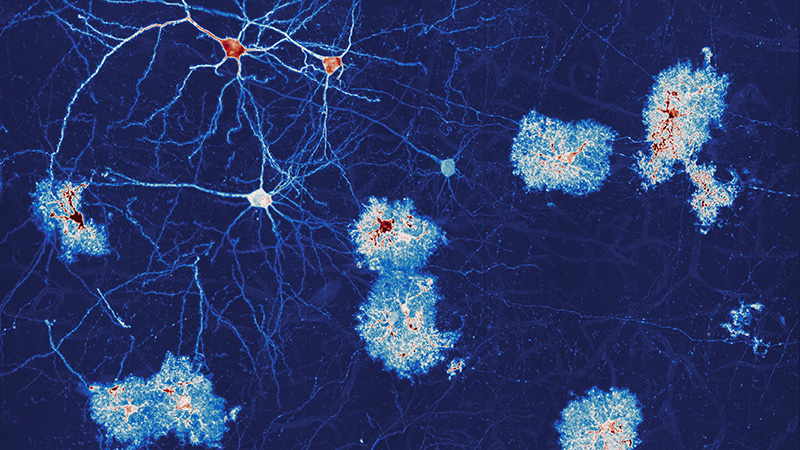
Closing Thoughts
What struck me most in this episode was not the scale of the challenges but the clarity of thinking behind them. Between Kate’s cell-by-cell reconstruction of development and Jan’s software-centric engineering philosophy, it becomes clear that light-sheet microscopy is entering a new era, one where biology and computing are inseparable.
The microscope is no longer just an optical device; it is a computational instrument.
The future belongs to those who can see not only the cells, but the data behind them.


References
- “Method of the Year 2014,” Nat Methods, vol. 12, no. 1, pp. 1–1, Jan. 2015, doi: 10.1038/nmeth.3251.
- K. McDole et al., “In Toto Imaging and Reconstruction of Post-Implantation Mouse Development at the Single-Cell Level,” Cell, vol. 175, no. 3, pp. 859-876.e33, Oct. 2018, doi: 10.1016/j.cell.2018.09.031.
- D. Mahecic, W. L. Stepp, C. Zhang, J. Griffié, M. Weigert, and S. Manley, “Event-driven acquisition for content-enriched microscopy,” Nat Methods, vol. 19, no. 10, pp. 1262–1267, Oct. 2022, doi: 10.1038/s41592-022-01589-x.
- M. Jan, A. Spangaro, M. Lenartowicz, and M. Mattiazzi Usaj, “From pixels to insights: Machine learning and deep learning for bioimage analysis,” BioEssays, vol. 46, no. 2, p. 2300114, 2024, doi: 10.1002/bies.202300114.
- F. Amat, B. Höckendorf, Y. Wan, W. C. Lemon, K. McDole, and P. J. Keller, “Efficient processing and analysis of large-scale light-sheet microscopy data,” Nat Protoc, vol. 10, no. 11, pp. 1679–1696, Nov. 2015, doi: 10.1038/nprot.2015.111.
- A. Julia, R. Iguernaissi, F. J. Michel, V. Matarazzo, and D. Merad, “Distortion Correction and Denoising of Light Sheet Fluorescence Images,” Sensors (Basel), vol. 24, no. 7, p. 2053, Mar. 2024, doi: 10.3390/s24072053.
- M. M. Rahman and D. N. Davis, “Addressing the Class Imbalance Problem in Medical Datasets,” IJMLC, pp. 224–228, 2013, doi: 10.7763/IJMLC.2013.V3.307.
- E. C. Kugler et al., “Zebrafish Vascular Quantification (ZVQ): a tool for quantification of three-dimensional zebrafish cerebrovascular architecture by automated image analysis,” Development, p. dev.199720, Jan. 2022, doi: 10.1242/dev.199720.


